WEEK 14
8 Hashing
8.1 General Idea
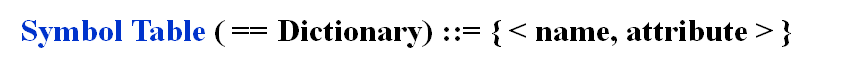
Symbol Table ADT
- Objects : A set of name-attribute pairs, where the names are unique
- Operations :
- SymTab Create(TableSize)
- Boolean IsIn(symtab, name)
- Attribute Find(symtab, name)
- SymTab Insert(symtab, name, attr)
- SymTab Delete(symtab, name)
Hash Tables
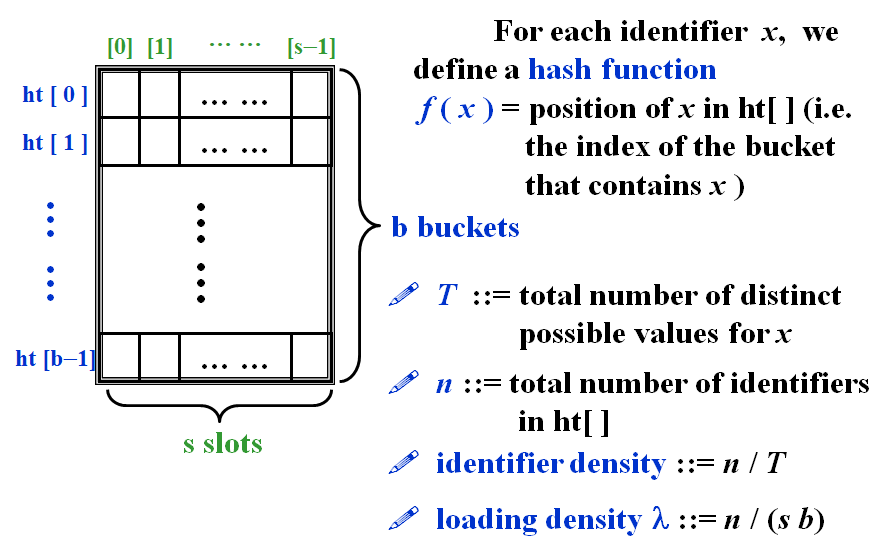
- A collision occurs when we hash two nonidentical identifiers into the same bucket.
- An overflow occurs when we hash a new identifier into a full bucket.
8.2 Hash Function
- \(f(x)\) must be easy to compute and minimize the number of collisions.
- \(f(x)\) should be unbiased. For any \(x\) and any \(i\), we have that \(Probability(f(x)=i)=\frac{1}{b}\). Such kind of a hash function is called a uniform hash function.
8.3 Separate Chaining
- keep a list of all keys that hash to the same value
Create an empty table
Find a key from a hash table
| C | |
|---|---|
Insert a key into a hash table
Note : Make the TableSize about as large as the number of keys expected (i.e. to make the loading density factor \(\lambda\approx\)1).
8.4 Open Addressing
- find another empty cell to solve collision(avoiding pointers)
Note : Generally \(\lambda<0.5\).
Linear Probing
- \(F(i)\) is a linear function of \(i\), such as \(F(i)=i\).
- 逐个探测每个单元(必要时可以绕回)以查找出一个空单元
- 使用线性探测的预期探测次数对于插入和不成功的查找来说大约是\(\frac{1}{2}(1+\frac{1}{(1-\lambda)^2})\),对于成功的查找来说是\(\frac{1}{2}(1+\frac{1}{1-\lambda})\)
- Cause primary clustering : any key that hashes into the cluster will add to the cluster after several attempts to resolve the collision.