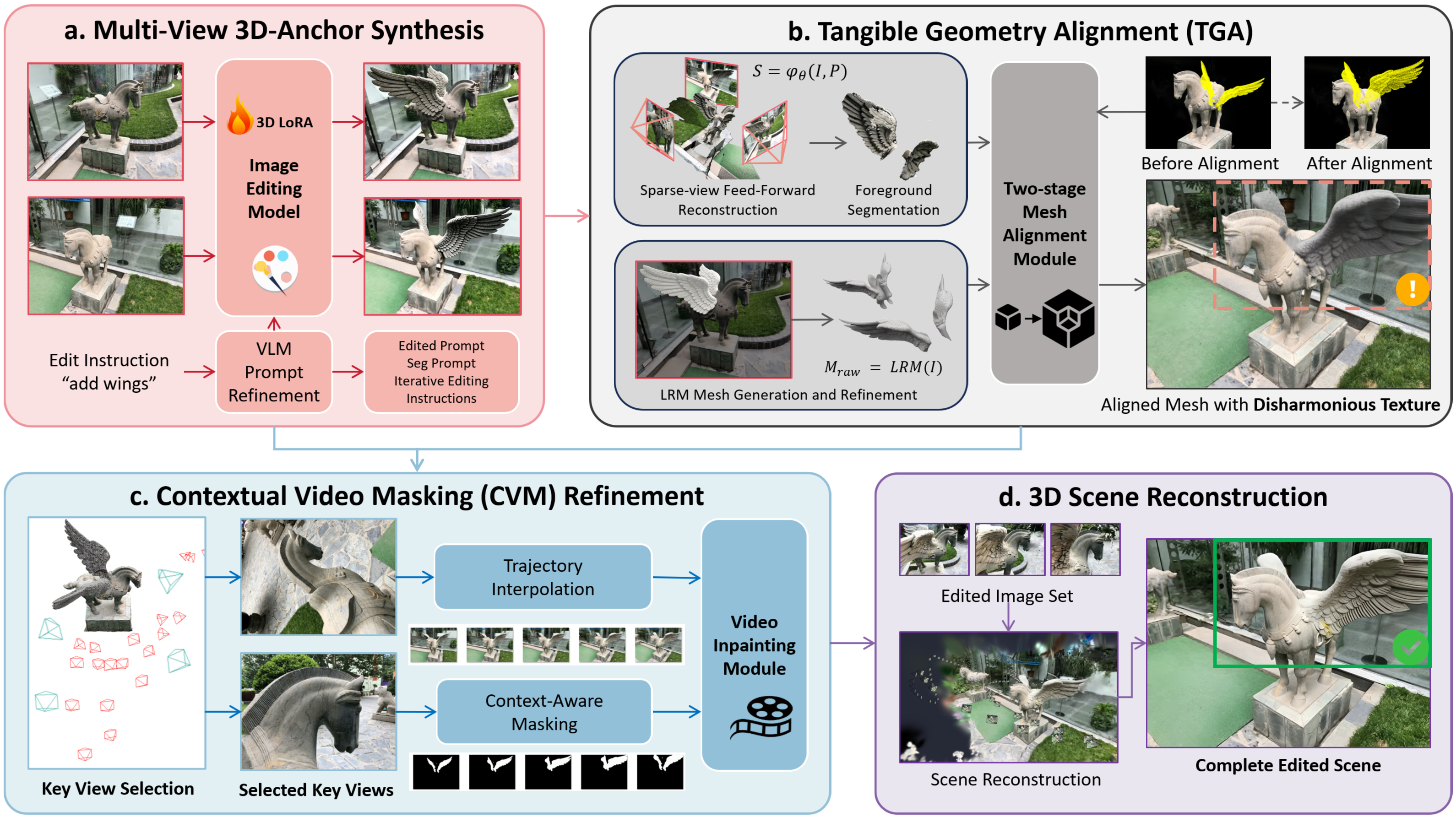
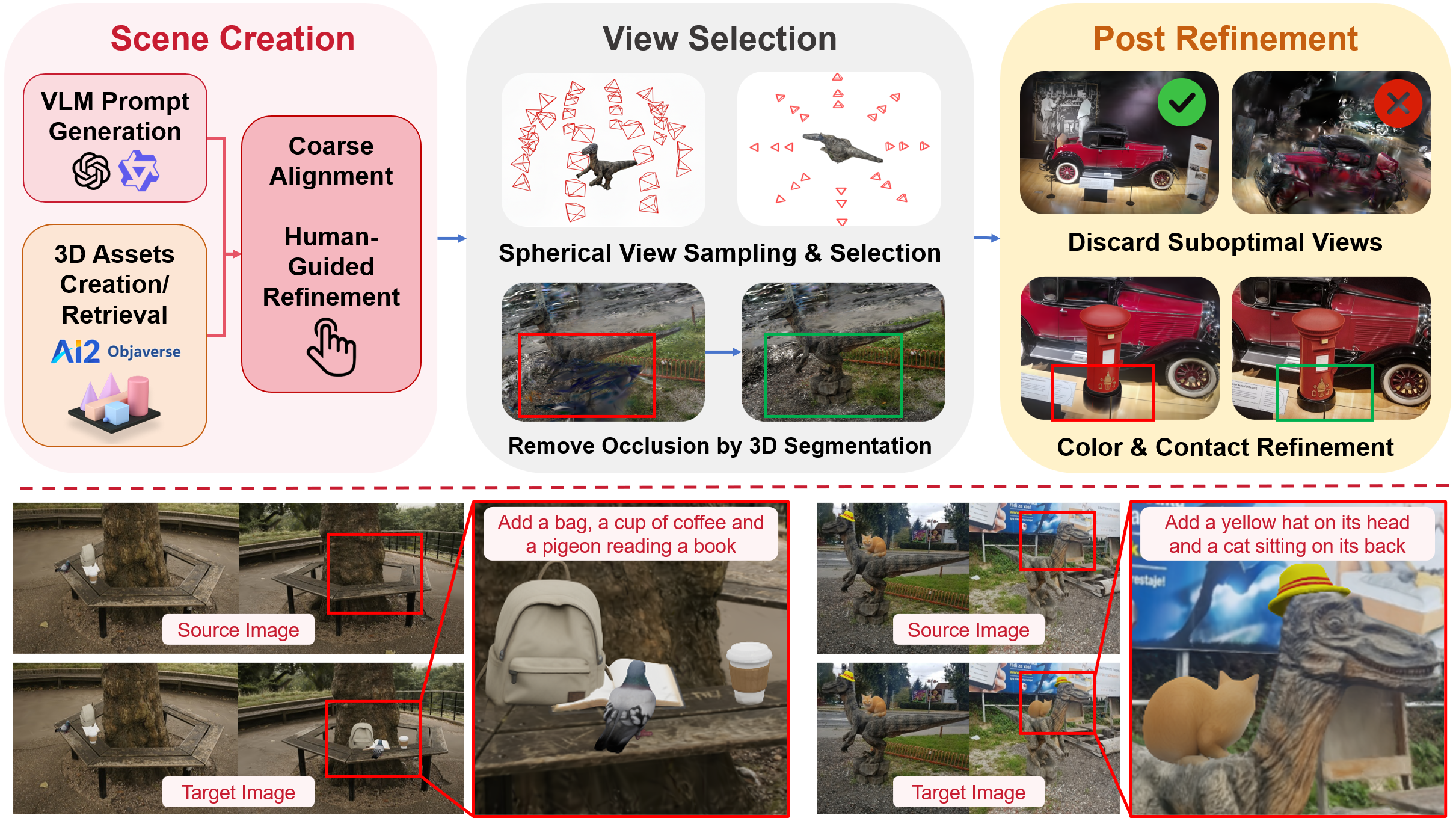
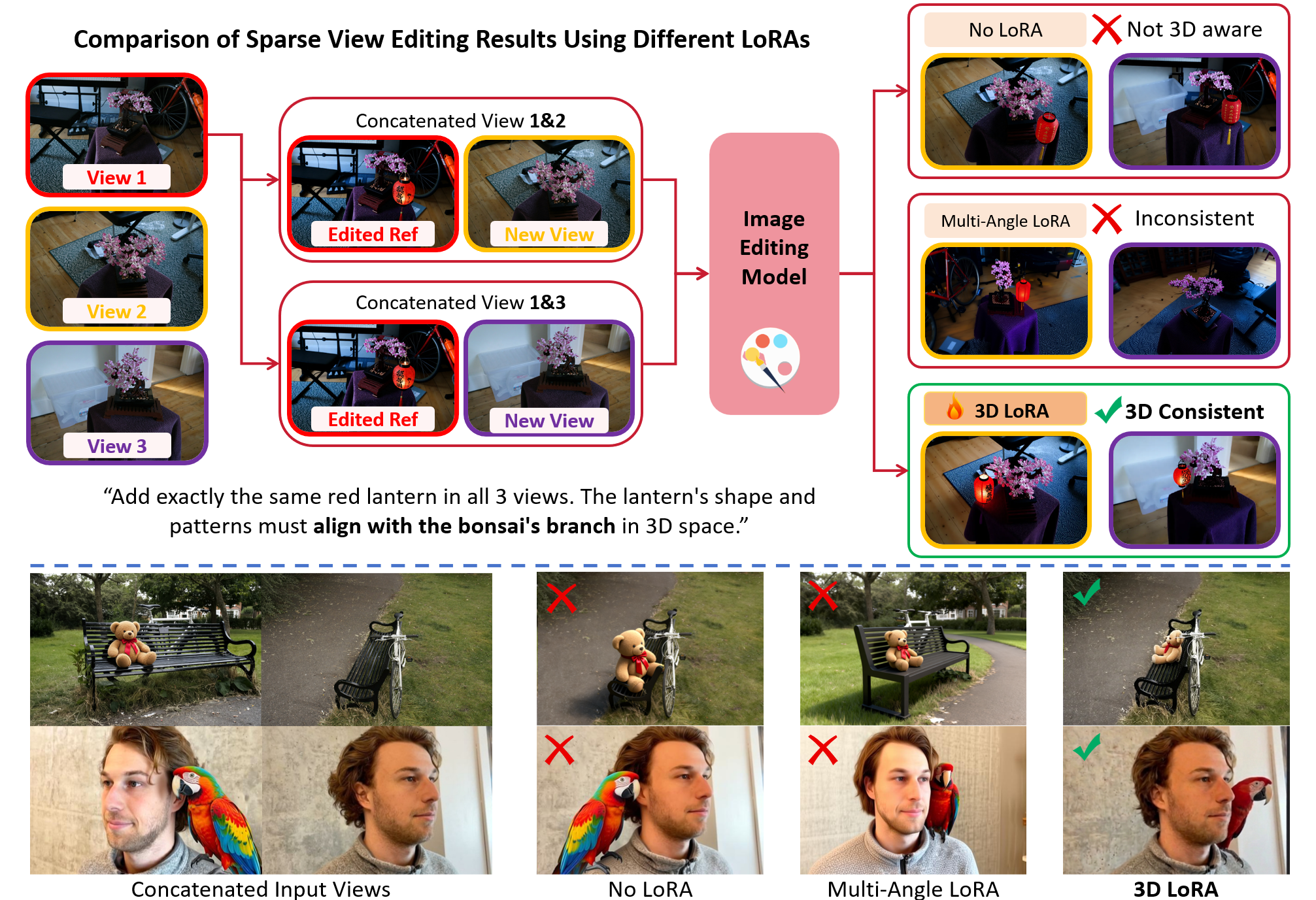
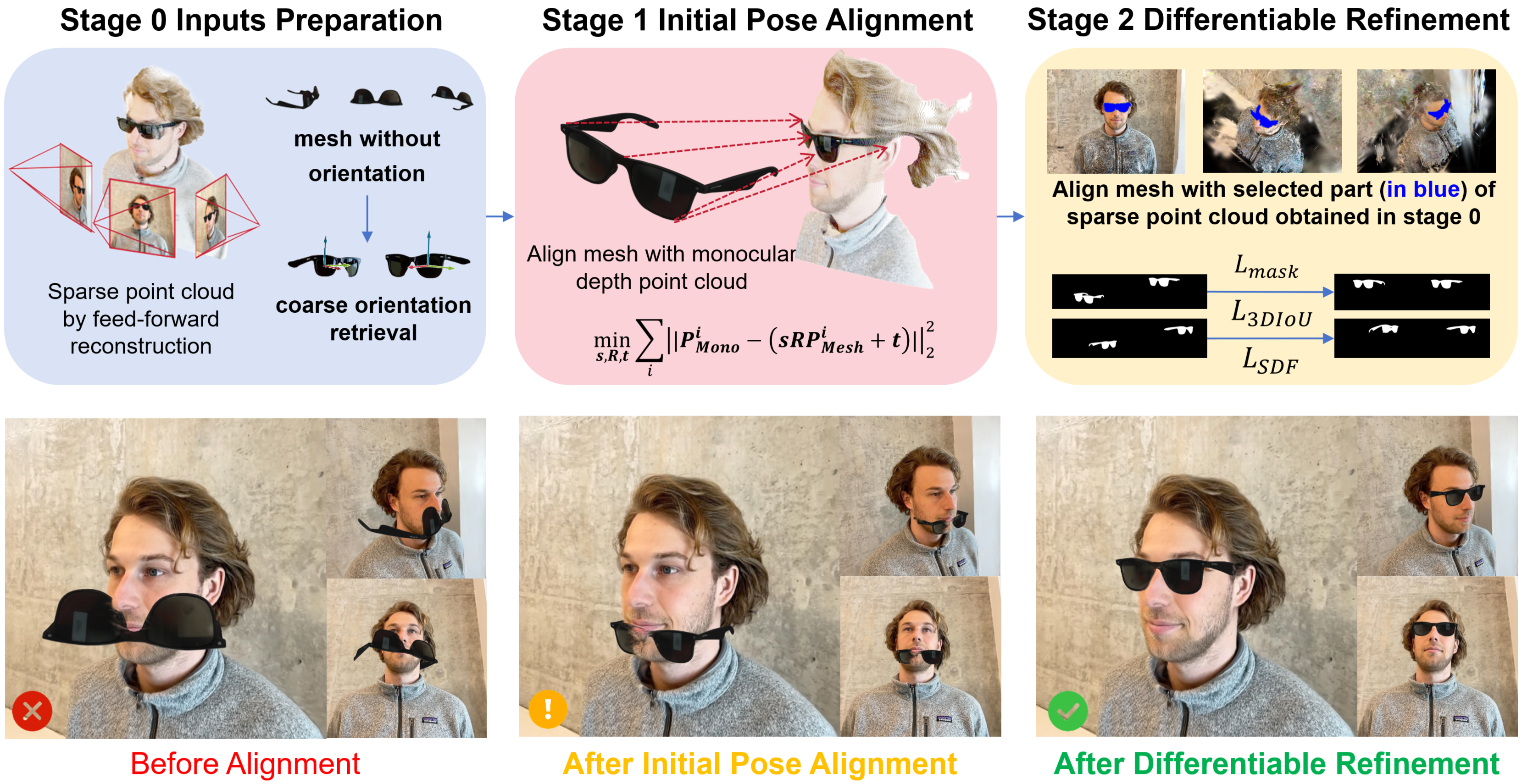
Quantitative
Benchmark Comparison
We evaluate on a benchmark of 8 scenes collected from IN2N, BlendedMVS, and Mip-NeRF 360, covering both geometry transformation and style transfer tasks with roughly 6 editing cases per scene. TRACE improves semantic alignment, structural consistency, and perceived visual quality while keeping runtime competitive with feed-forward baselines.
| Method | Pub. | CLIPdir ↑ | CLIPsim ↑ | DINO ↑ | Aesthetic ↑ | Time ↓ |
|---|---|---|---|---|---|---|
| DGE | ECCV'24 | 0.0655 | 0.2371 | 0.8849 | 5.7974 | 10 min |
| GaussCtrl | ECCV'24 | 0.0446 | 0.2126 | 0.8962 | 5.5164 | 20 min |
| TIP-Editor | SIG'24 | 0.1013 | 0.2316 | 0.8534 | 5.3854 | 45 min |
| GaussianEditor | CVPR'24 | 0.0680 | 0.2254 | 0.8671 | 5.4307 | 16 min |
| EditSplat | CVPR'25 | 0.0762 | 0.2299 | 0.8834 | 5.8071 | 18 min |
| Vipe3dedit | AAAI'25 | 0.0331 | 0.2154 | 0.8831 | 5.6823 | 10 min |
| TRACE | --- | 0.1514 | 0.2465 | 0.9058 | 6.1035 | 10 min |